This guide will show another approach that does not involve any of these.
Instead, it will be using a combination of Excel’s functions: INDEX, OFFSET, MATCH and COUNTIF.
In this example, we will be taking a data set with different Divisions, along with the Apps that belong to each division.
The aim here is to get a unique list of divisions, which we will then use to create a dynamic dropdown list.
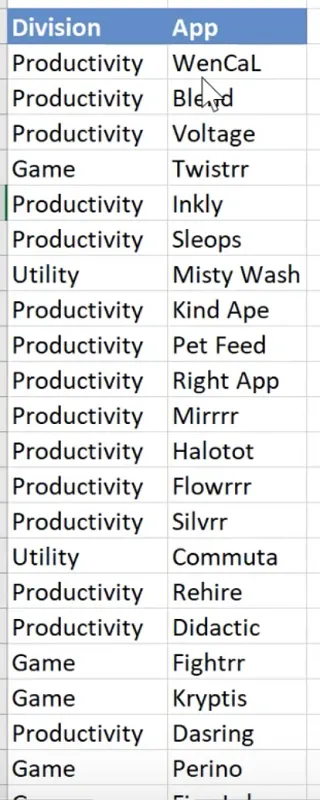
Moreover, this list should be able to expand accordingly when new divisions or apps are added to the data set.
Convert data set into an Excel data table
In order to keep this solution dynamic regardless if a new row is added in the middle or to the end of the data set, the table needs to be converted to an official Excel data table.
To do this, click anywhere in the data set.
Press CTRL + T to bring up the Create Table window dialog.
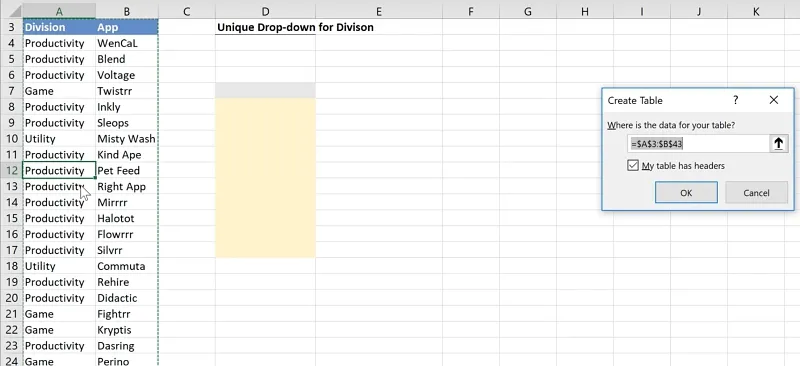
Make sure to tick the box for “My table has headers”.
Click OK.
You can then format the table as you prefer, or Clear formatting by going to the Design tab.
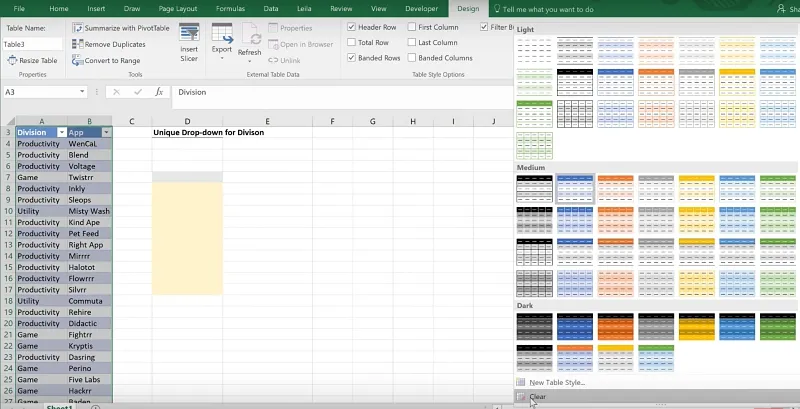
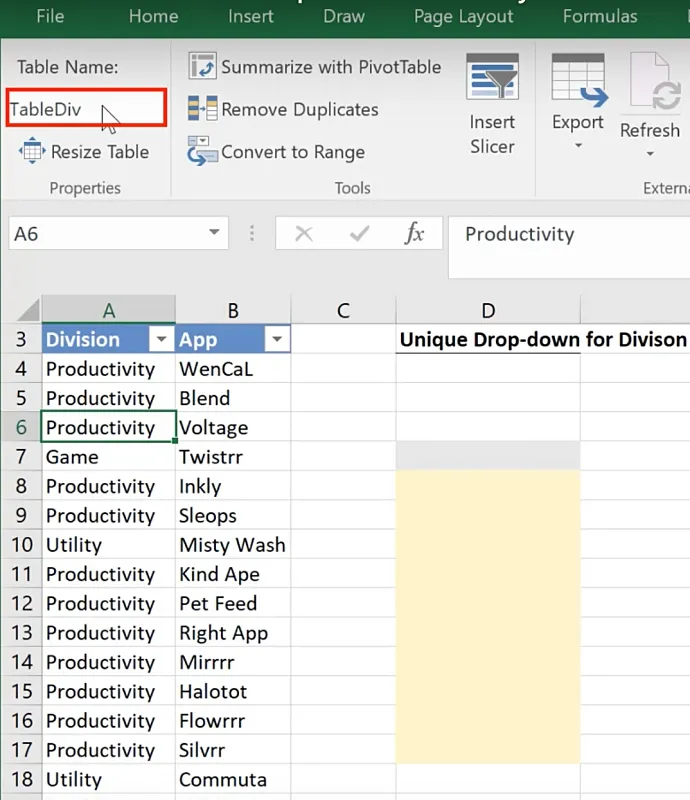
Rename the table for ease in referencing.
In this example, we use the name TableDiv.
Create a unique list
Create a list that summarizes the unique Division values in the data table.
One approach is to use the INDEX() function, where you can specify how many rows to go down for the formula to get to the next value that hasn’t occurred in the list yet.
To start:
Cell D8 = INDEX(array,row_num,[column_name])- array – The area where the result can be found. In this case, it is TableDiv[Division].
- row_num – How many rows going down it should move. In this case, the first occurrence is going to be unique since there is nothing on the list yet, and therefore we set it as 1.
- [column_num] – How many columns to the right it should move. This is an optional argument which we can leave blank since we only have one column.
Cell D8 = INDEX(TableDiv[Division],1)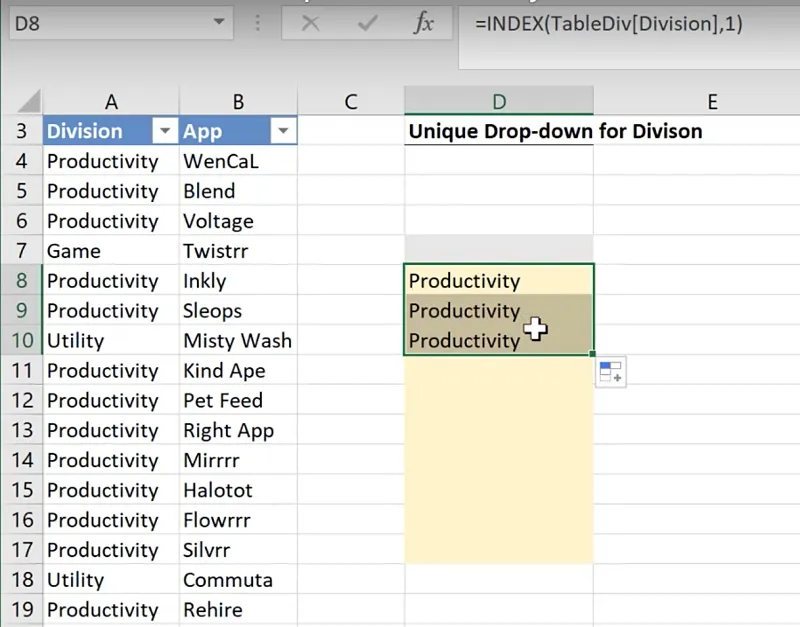
However, notice that if you want to pull this formula down, all three cells display the same result as cell D8.
You will need to have a dynamic row_num argument that returns the value of the next cell with a unique value:
- Cell D8 = Productivity, row 1 (cell A4)
- Cell D9 = Game, row 4 (cell A7)
- Cell D10 = Utility, row 7 (cell A9)
Make the row_num argument dynamic based on the occurrences that have already happened and then finding that value in the source data.
The logic is that if “Productivity” has already occurred in the list, the formula should find and ignore all the occurrences of “Productivity”.
At the same time, as you drag the formula down, the formula should take into account all the values that are already in the list, thereby expanding the range, and then disregard those values in the source data accordingly.
Normally, the COUNTIF() function does not immediately come to mind such situation.
While it is primarily used to count the number of occurrences in a given range, you can actually tweak its use.
The syntax for this formula is:
=COUNTIF(range, criteria)If you write =COUNTIF(A4:A10,D8), it tells you that there are 5 occurrences of “Productivity” in the range A4:A10.
However, if you swap the placed of criteria and range by writing:
= COUNTIF(D8,A4:A10)it gives you 1 as an answer.
If you go to the formula bar and press F9, you will notice that there are, in fact, 7 answers in an array: {1;1;1;0;1;1;0}
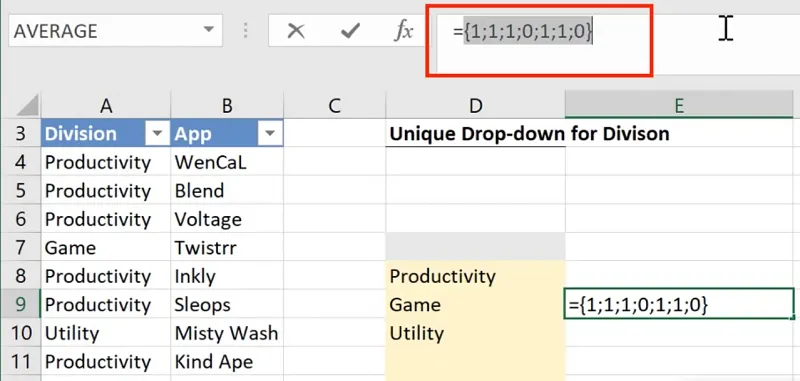
The 1’s indicate a TRUE when matching cell D8 with a cell in the range, and 0’s indicate a FALSE.
The array {1;1;1;0;1;1;0} implies that in the range specified, cells 4 and 7 are not equal to “Productivity”. (Note: To undo the display of the array result, press CTRL + Z.)
This information can then be used to find the first 0 in this list by integrating the MATCH() function.
=MATCH(lookup_value, lookup_array, [match_type])- lookup_value – 0
- lookup_array – the COUNTIF() function above
- match_type – exact match, 0
The final formula becomes:
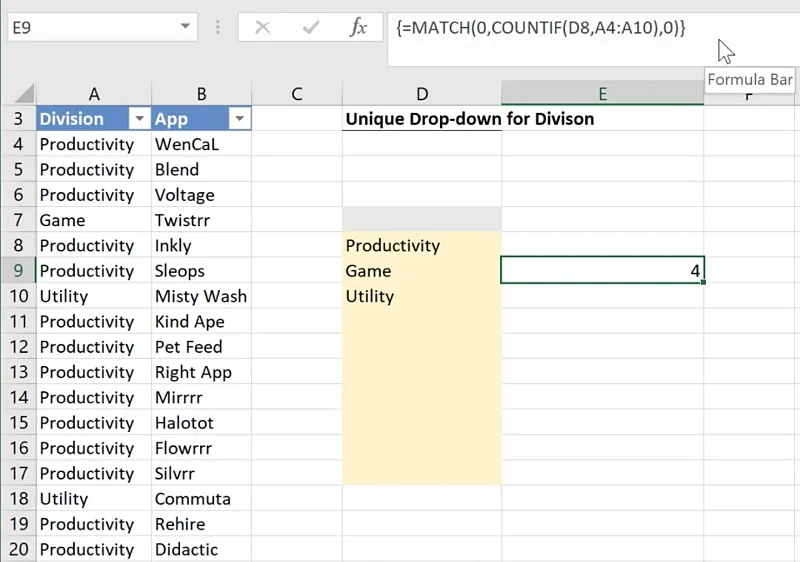
Cell E9 = MATCH(0,COUNTIF(D8,A4:A10),0)However, when pressing ENTER, it results to an #N/A error.
This is because MATCH()is not programmed to be an array function.
You will have to go to the formula bar and press CTRL + SHIFT + ENTER to convert the formula into an array.
An alternative approach that does not involve the use of CSE is to wrap the lookup_array inside an INDEX() function because INDEX() is a pre-programmed CSE function.
An important thing to note is that the row_num argument of INDEX() is required and not optional.
To address this, the separator (,) will be used.
The formula now becomes:
Cell E9 = MATCH(0,INDEX(COUNTIF(D8,A4:A10),),0)Dragging this formula down, you will notice that cell E10 does not give a 7.
This is because it is only looking at “Game” in cell D9, instead of both D8 and D9.
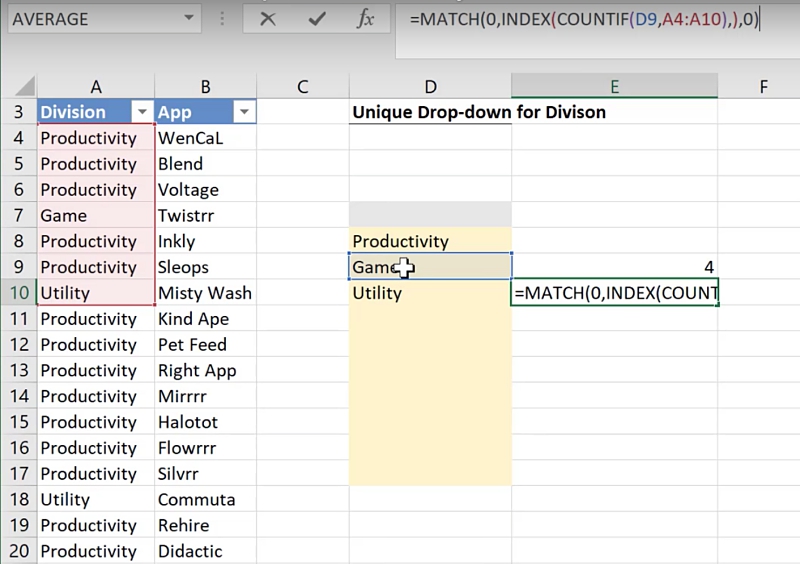
To fix this, expand the first argument in the COUNTIF() function to include cell D8:
Cell E9 = MATCH(0,INDEX(COUNTIF(D8:D9,A4:A10),),0)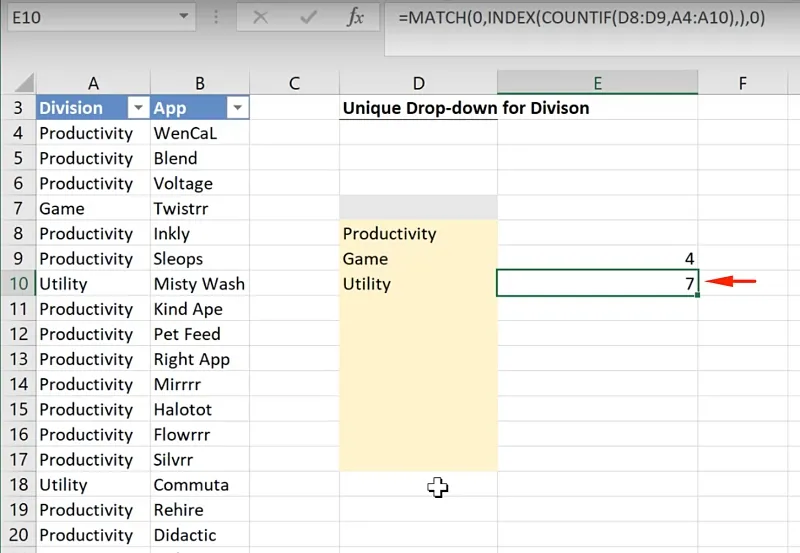
Rewrite the actual formulas in cell D8 accordingly.
Cell D8 =
INDEX(TableDiv[Division],
MATCH(0,INDEX(COUNTIF($D$7:D8,TableDiv[Division]),),0))When you pull this formula down to the last row, it now displayed unique Division names.

You will also notice that there are some #N/A errors.
This can be addressed by adding an IFERROR() function at the start to display an empty cell by default when the answer is an error.
Cell D8 = IFERROR(
INDEX(TableDiv[Division],
MATCH(0,INDEX(COUNTIF($D$7:D8,TableDiv[Division]),),0)),””)Again, pull this formula down to the last row.
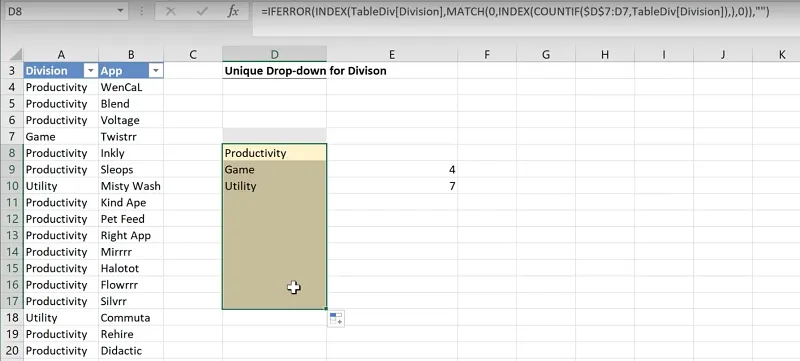
Adding a dynamic dropdown showing unique values
Click on the cell where you want the dropdown list to be.
Go to Data > Data Validation.
In the Validation criteria, select List.
Highlight the cells with the unique values ($D$8:$D$17) as the Source.
Make sure to include all the relevant cells.
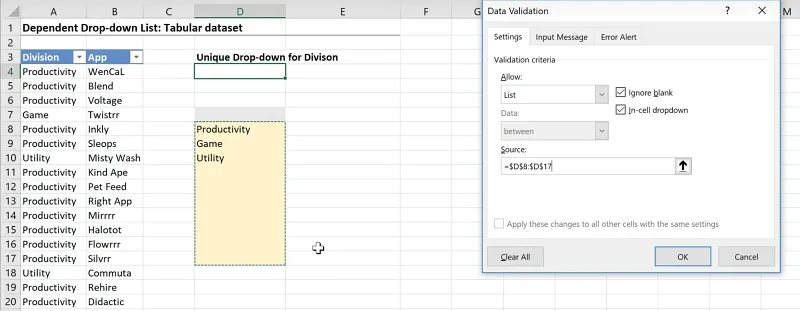
You will now have the dropdown list containing the unique values.
However, you will also notice that the dropdown list includes the empty cells too.
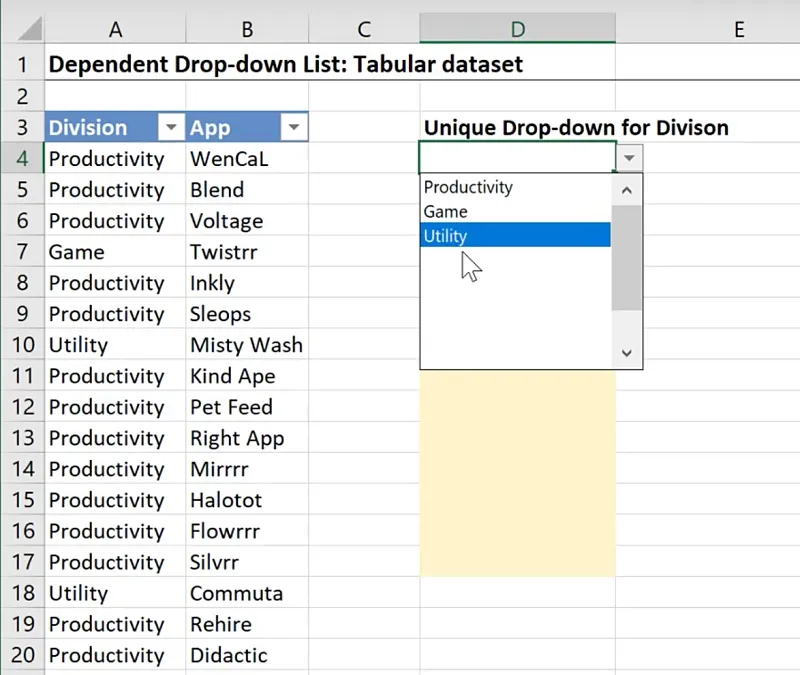
The size of the list changes depending on the values in the source table.
Thus, the formula should be changed into one that automatically adjusts the range.
The OFFSET() function can be used in this situation. (A detailed walkthrough can be found here.)
In order to easily see the result, test the formula in the spreadsheet instead of writing it directly in the Data Validation window.
= OFFSET(reference, rows, cols, [height], [width])- reference – This is the starting point. In this case, it is the first unique value in the list, D8.
- rows – How many rows you want to move down. Since you don’t want to move down, this is set as blank. Since this is a required argument, use a (,) separator.
- cols – How many columns to the right you want to move. You also don’t need to move any columns so this is also set as blank by using a (,) separator.
- [height] – The height of the range or the number of rows. This needs to automatically adjust based on how many unique values there are in the list. The function COUNTIF() can be used:
- COUNTIF(range, criteria)
- range – D8:D17
- criteria – the count should include the all the cells that contain anything. Wildcards can be used here such as: ? (any text) and * (as many characters long).
- [width] – an optional argument that refers to the width. Since there is only 1 column, this can be left as blank.
- COUNTIF(range, criteria)
The final formula becomes:
Cell E8 = OFFSET(D8,,,COUNTA(D8:D17,”?*”))Upon hitting ENTER, it returns “Productivity”, which is merely the first value in the array.
To see the full set of values in the result, click on the formula bar and press F9:
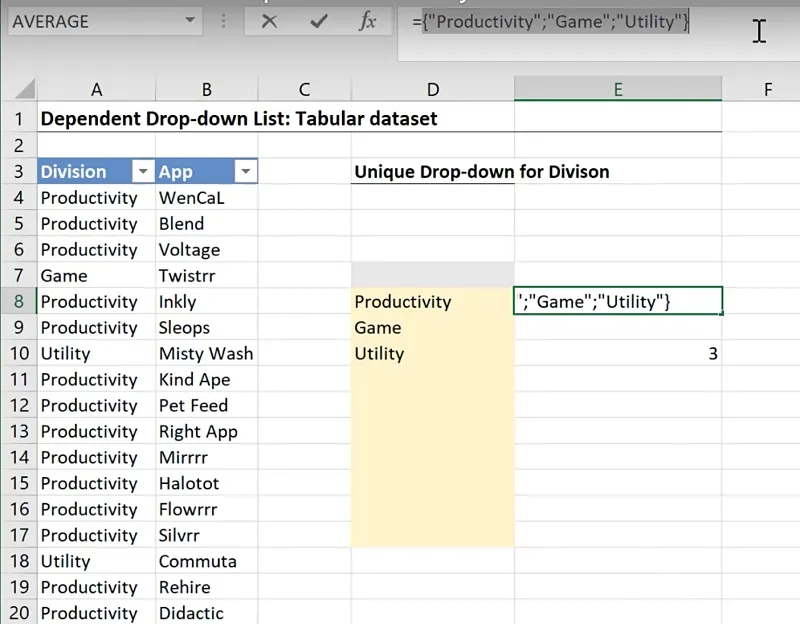
From the D8:D17 range, it displays the three values: “Productivity”, “Game”, and “Utility”.
It effectively disregards the empty cells. (Note: Press CTRL + Z to revert back to the formula.)
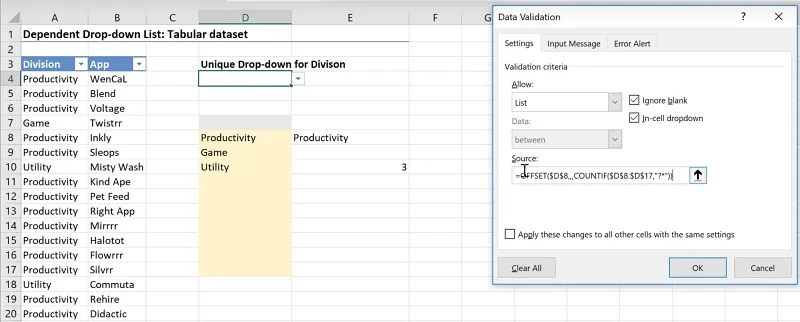
Before using this formula in the Data Validation, make sure the cell references are fixed.
Cell E8 = OFFSET($D$8,,,COUNTA($D$8:$D$17,”?*”))Copy the entire formula from the formula bar.
Select cell D4, which is where you want the dropdown to be shown.
Go to Data > Data Validation.
Paste the formula as the Source.
It should now display the correct dropdown values, excluding any blank entries from D8:D17.
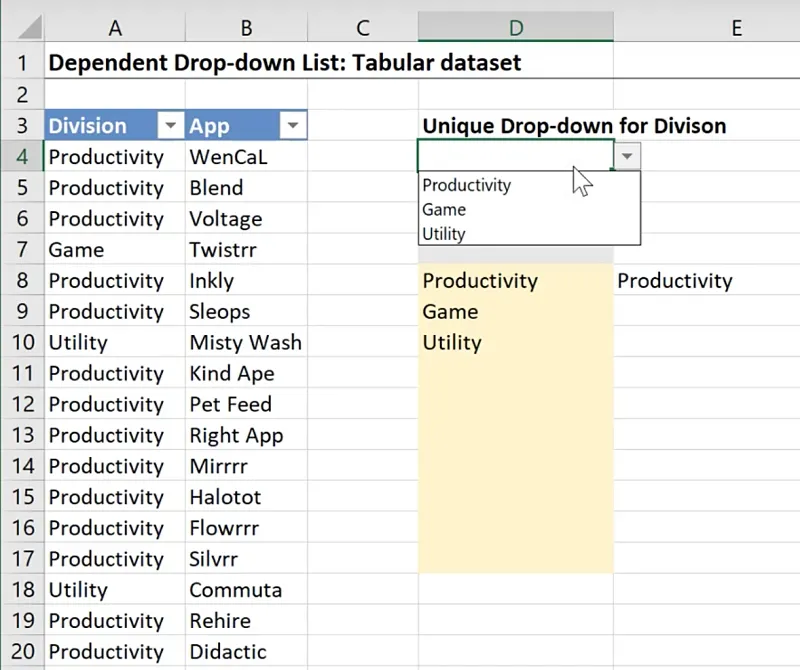
You can test this out by adding new Division values in the table and see if the dropdown is updated accordingly with no duplicates.
Using the COUNTA() function in the OFFSET() function
When specifying the [height] in the OFFSET() function, the COUNTA() function will still give you the empty spaces you don’t need.
This is because the formula written in cells D8 to D17 will return a blank as its default value, and blanks are counted as text in the COUNTA() function.
Thus, using the formula COUNTA(D8:D17) will return a value of 10 instead of 3.
In effect, if the COUNTA() function is used in the [height] argument:
COUNTA(value1, [value2], …)- value1, value2, … – the range of cells you want to return a count when they are not empty. In this case, D8:D17
Cell E8 = OFFSET(D8,,,COUNTA(D8:D17))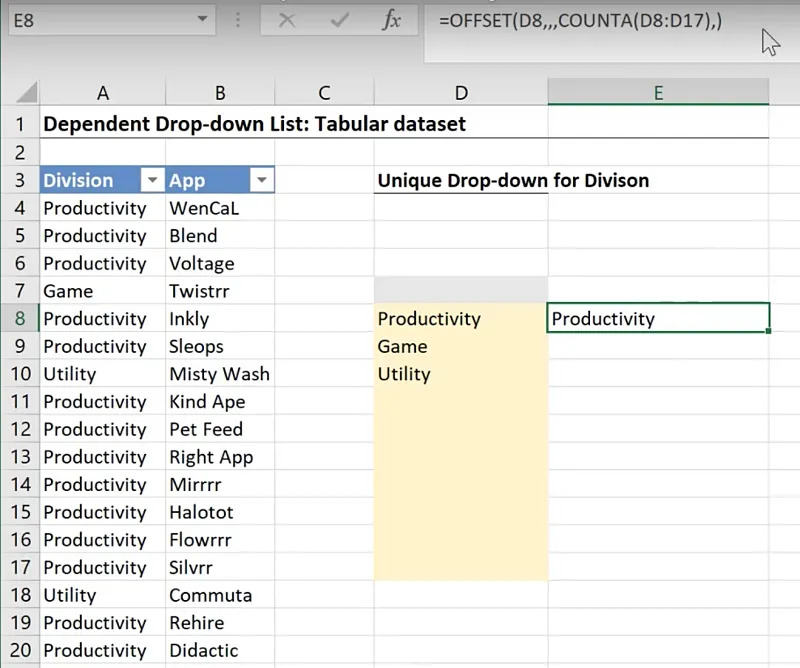
Click on the formula bar and press F9:
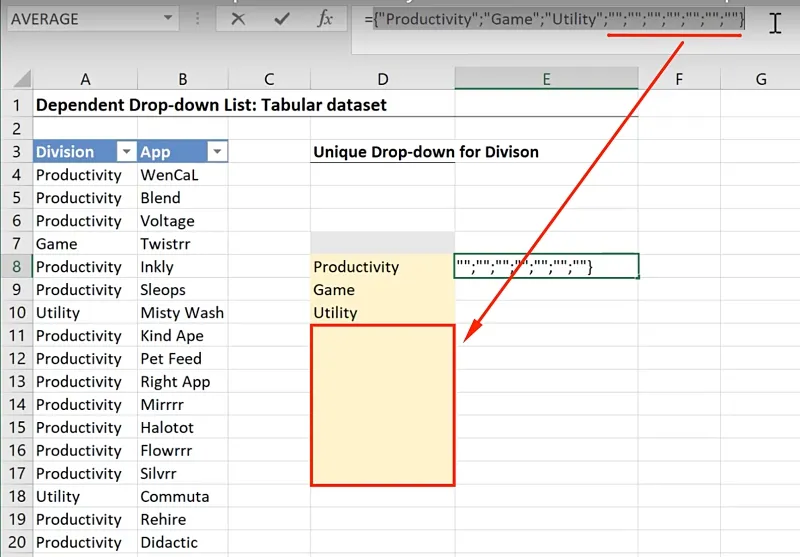
It returns:
={“Productivity”;“Game”;“Utility”;”” ;”” ;”” ;”” ;”” ;”” ;””}You will notice that it includes some empty ones which correspond to cells D11:D17.
Press CTRL + Z to revert back to the formula.
If you take a look at the formula in cell D11, it uses a blank as its default value:
Cell D11 = IFERROR(
INDEX(TableDiv[Division],
MATCH(0,INDEX(COUNTIF($D$7:D10,TableDiv[Divisions]),),o)),””)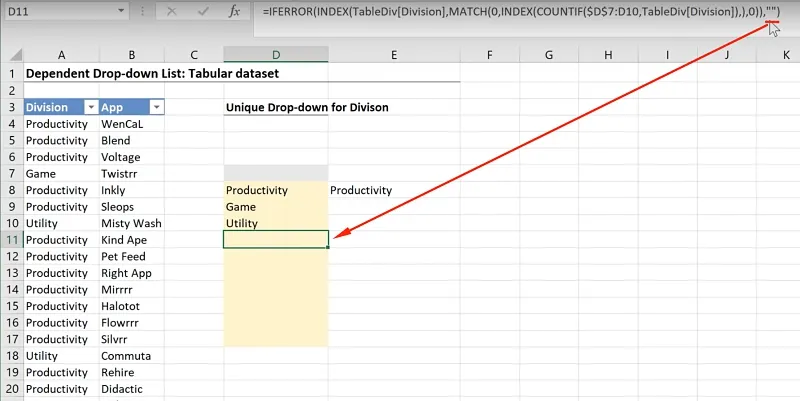
Feel free to Download the Workbook HERE.
If you’re interested to find out the dependent drop-down list based on this table can be setup, make sure you check out this tutorial! It uses some advanced formula techniques to the get the job fun. Lots of fun to setup!

Leila Gharani
I'm a 6x Microsoft MVP with over 15 years of experience implementing and professionals on Management Information Systems of different sizes and nature.
My background is Masters in Economics, Economist, Consultant, Oracle HFM Accounting Systems Expert, SAP BW Project Manager. My passion is teaching, experimenting and sharing. I am also addicted to learning and enjoy taking online courses on a variety of topics.