Imagine we create a template to be filled out by different people. We send the template to our team members and await their replies.
After a few days, we receive multiple responses in the form of separate tables.

Before we can report on the results, we need to combine the results into a single table.
This combining process is not difficult, but it can become time-consuming and tedious.
The worst of it all is when you receive additional submission once your report is built that need to be integrated into the master data set, then all reports have to be refreshed to “see” the newly added data.
Again… time-consuming and tedious.
Prepare to Be Amazed
Our most amazing set of data gathering tools known as “Get & Transform Data” (most of us call it by the name it had before it became famous, “Power Query”), has a feature whereby you can point to a folder, filter out all the unwanted files, then combine the wanted files’ data into a single table suitable for charting, sorting, filtering, and pivoting.
The standout feature is its ability to absorb new files and their data as soon as the file is added to the folder.
You don’t even have to open the files; just paste the file into the folder and you’re done.
(To be fair, you may have to click one more time to update the reports, but even that can be automated with a bit of VBA code.)
Featured Course
Black Belt Excel Package

The Problem
We have a folder where we have saved all the returned templates discussed earlier.
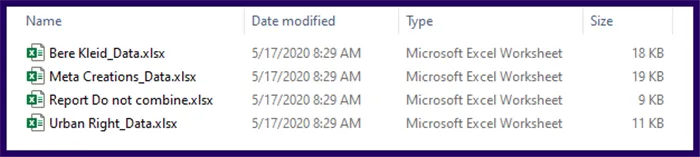
We don’t want to combine EVERY file in the folder:
- We only want to get data from files that end with “_Data” in their filename
- We want to include only Excel files; files that contain a .XLS, .XLSX, .XLSM, or .XLSB extension
File Structure and Content
Looking at one of the file submissions, we can see the file contains a table made up of sales information.
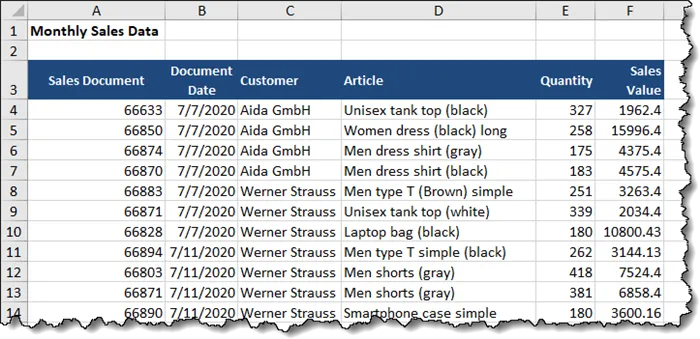
Because these files were based on a template, the structure is identical across files, but the data is different.
At present, we have a file named “Report Do Not Combine.xlsx” that needs to be excluded from the data gathering process.

Desired End Result
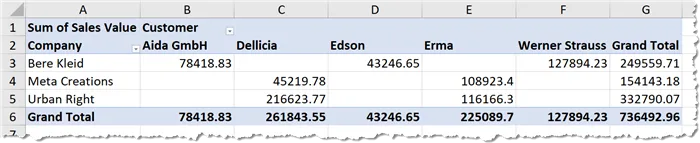
We wish to produce a Pivot Table that combines the data from the desired files to produce a summarized sales report by company and customer.
Creating the Query using Get & Transform Data
We begin by starting Excel and creating a new blank workbook.
Next, we begin creating the query by selecting Data (tab) -> Get & Transform Data (group) -> Get Data -> From File -> From Folder.
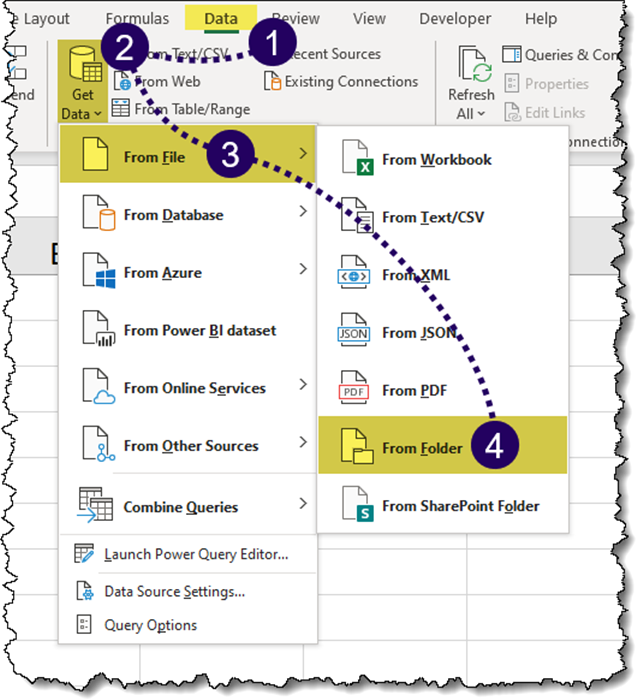
In the Folder dialog box, click the “Browse…” button to select the folder containing the desired files and click OK.
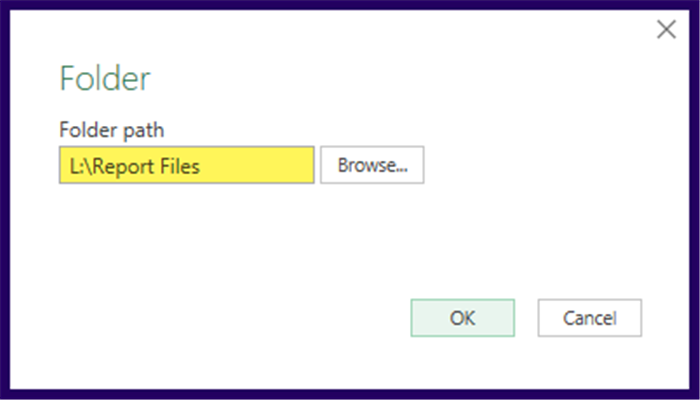
Power Query will display a list of the folder’s contents in a preview window.
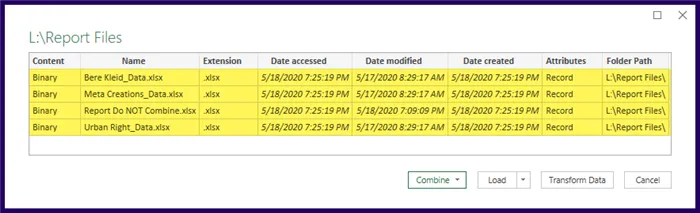
If the folder contained ONLY the needed files AND we knew the files were in perfect structural order requiring no alterations, we could click the Combine button and be done with it.
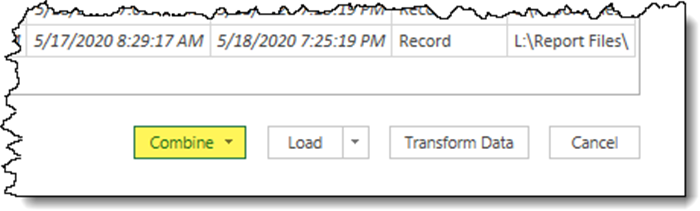
Data rarely requires NO adjustments, as is our present case, so we will click the Transform Data button to load the folder contents into Power Query.
Selecting Only the Desired Files
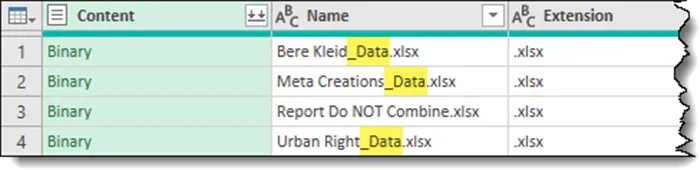
Before we combine the files in the selected folder, we need to ensure that unwanted files are not included in the process.
In our scenario, we only want to include files that contain the character string “_Data” in the filename.
To isolate only these files, click the Filter button (top-right of the column) and select Text Filter -> Contains…
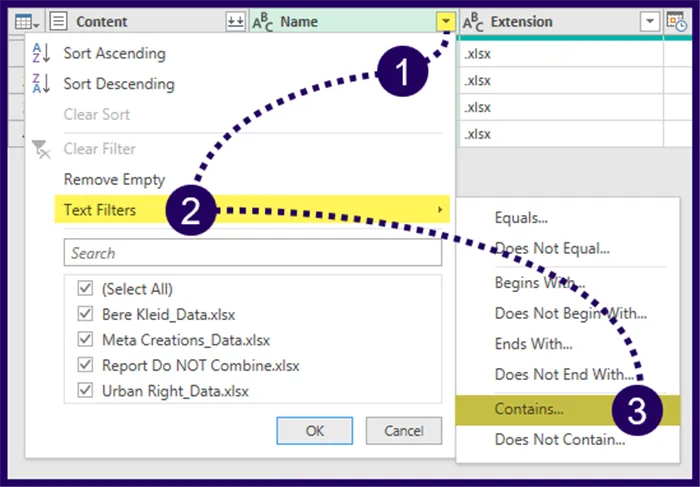
In the Filter Rows dialog box, we will set the filter to “Keep rows where ‘Name’ contains “_Data”.
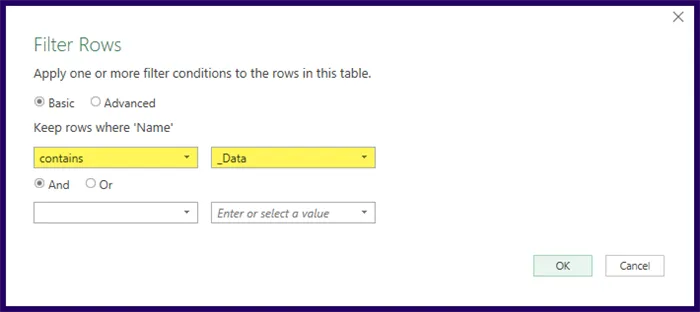
Technically, we could set the filter to contain files that only contain “_” (an underscore), but this could be risky if someone saves a file with an underscore in the file for reasons other than our own. “_Data” is less likely to occur in another user’s naming scheme.
We have now filtered out any files that fail to contain the required naming pattern.
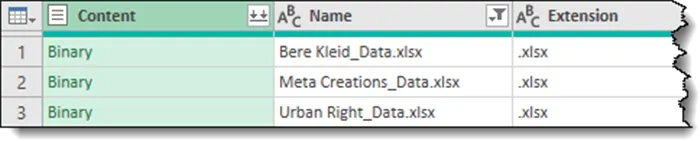
We also want to ensure we select only Excel files (.XLS, .XLSX, .XLSM, and .XSLB files).
Let’s filter the Extension column to files that begin with “.xls”.
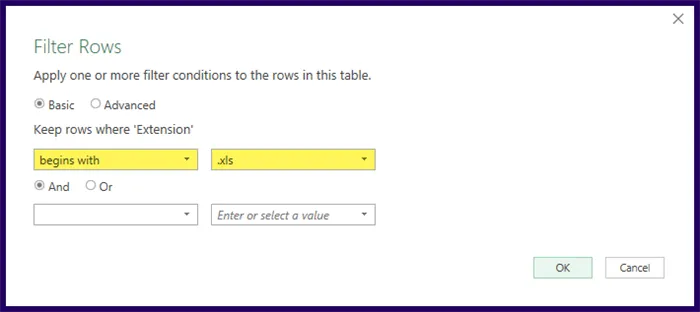
Although this step is unnecessary in this current example, it is a nice “future-proofing” step in case someone decides to save non-Excel files in this folder at a later date.
Featured Course
Master Excel Power Query – Beginner to Pro

Combining the Files into a Single Table
The next step is to combine the contents of each file into a single table. This is performed by clicking the Combine Files button located at the top-right of the Content column.
I like to refer to it as the “Sad Robot” button. Just look at it. Doesn’t it remind you of a sad robot?

In the Combine Files dialog box, a preview of the file contents is listed and presented based on the first file in the list.
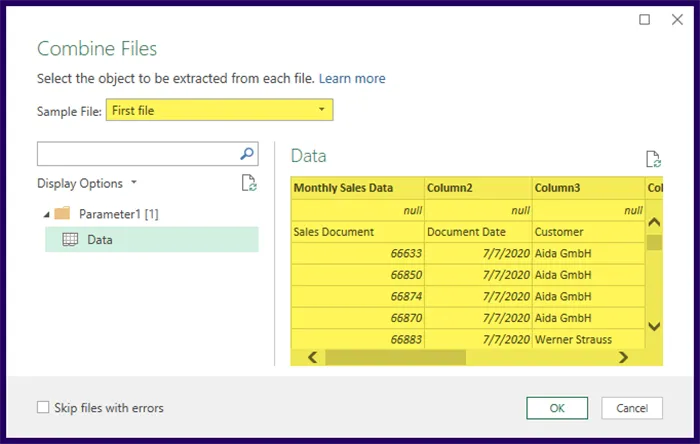
If this representation appears correct, click OK to execute the data extraction and combining process.
Power Query will perform the following actions:
- Evaluate the data in the first file
- Apply the same transformation steps to the remaining files in the folder
- Combine the transformation results into a single table
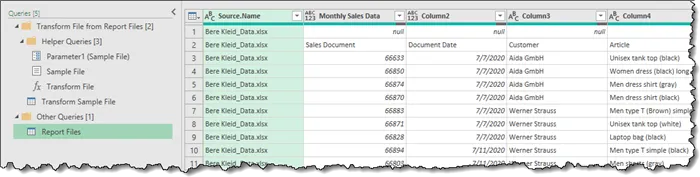
NOTE: The name of the query is “Report Files” because that was the name of the folder that contains the files. You can feel free to rename this query if you wish.
All the work performed on the files can be seen listed on the left of the screen in the Queries panel.
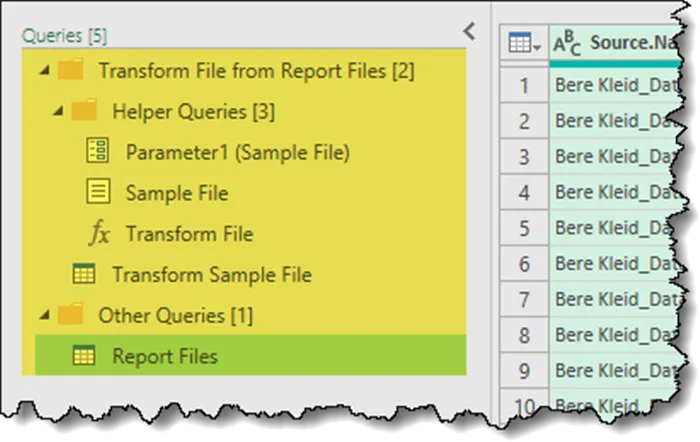
Applying Additional Transformations
Unfortunately, the results of the combining process are not perfect because the data was not presented in proper Excel Data Tables, so certain transformations were made based on assumptions that may not have been correct.
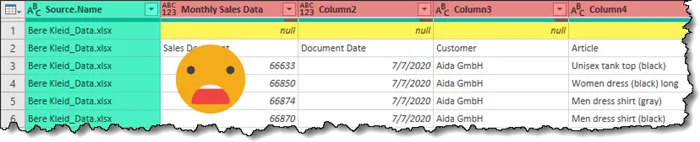
Headers are not correct, there are blank lines (nulls) in the data, file names are listed with the records.
This is where things get a bit technical because we must examine at a deeper level what took place from the time we clicked the sad robot until now.
Examining Applied Steps
If you look at the right side of the Power Query Editor you will see a list of applied steps.
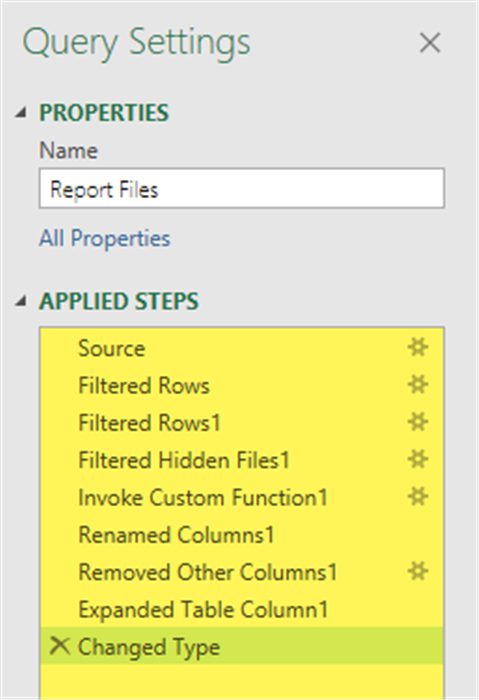
If you click from step to step through the list, you can see “snapshots in time”, or how the data looked after that specific step had completed. It’s almost like a time machine where you can go back in time and visit the data at any point in its processing.
Let’s quickly summarize the steps in our query:
- Connect to the data source (the folder)
- Filter out the files that don’t have “_Data” in their names
- Filter out non-Excel files
Here is where Power Query took over after we clicked the sad robot button.
- Filtered the folder contents to visible files only (those without an active “Hidden” attribute)
- Invoke a custom function that opens the sample file and determines where the data is located and attempt to locate the header rows. This extracts the file contents and stores them as nested tables in a new column.
- Renames the “Name” column to “Source.Name”
- Deletes all columns except “Source.Name” and the nested table’s column
- Expands the contents of the nested tables to create a new table displaying the file’s contents in a single table
- Attempt to assign proper data types to the columns (this step fails miserably due to incorrectly defined headers)
Adding Our Transformations
We know we need to “tweak” the query. The query made a gallant effort, but it fell short in a few key areas.
The question becomes where do we want to add our transformations?
If we click “Transform Sample File” in the queries panel, we can see how Power Query processed the first file.
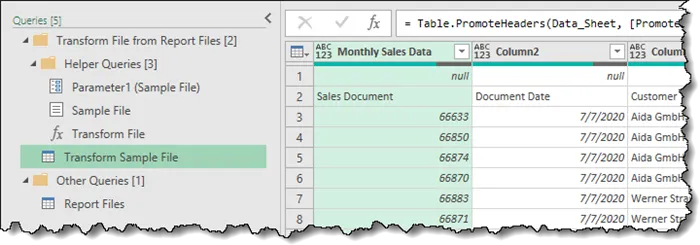
When we click “Report Files”, we see how all files were processed through the same steps applied to the sample file.
We need to determine if we want to adjust the steps made at the early stages of the query when working with the sample file, or at the later stage when we are the contents of the remaining files in the folder.
Word to the Wise: Many tasks can be performed at most any point during processing, but certain tasks can only be performed at certain points in time. The only way to know for sure when something needs to be performed is to experiment and see what works best for your given scenario. I know that’s not exactly concrete rocket-science level advice, but you’d be surprised how much of Power Query comes down to trial and error. The more you work with Power Query, the easier it becomes to know intuitively what works and when it works best.
Reducing and Renaming Data
Suppose we want the following additional transformations:
- “Source.Name” column to be called “Company”
- Company names should not contain “_Data.xlsx” in their names
Begin by “backing up” in the Applied Steps list to the “Removed Others Columns1” step.
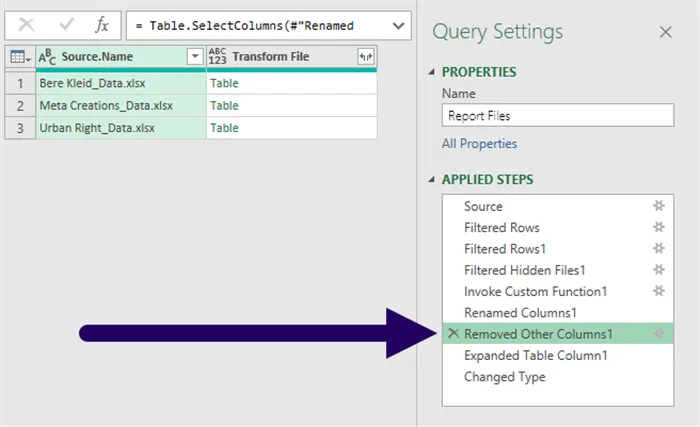
Rename the “Source.Name” column to “Company” (Transform (tab) -> Any Column (group) -> Rename) and click Insert if prompted.
Remove all the unwanted text from the company names by selecting Transform (tab) -> Text Column (group) -> Extract -> Text Before Delimiter. Click Insert if prompted to insert a step.
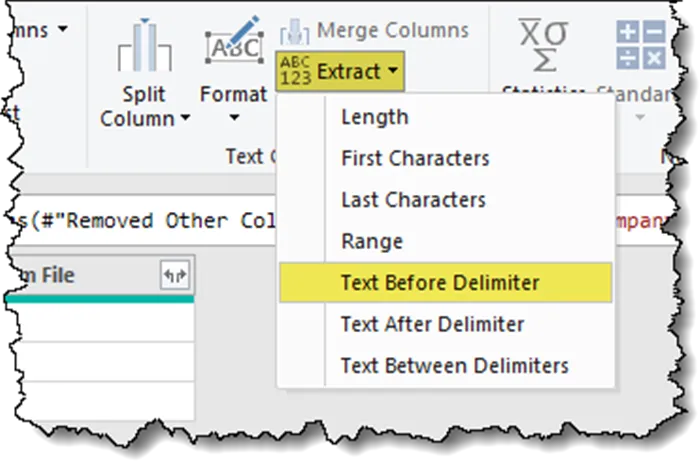
In the Text Before Delimiter dialog box, enter “_Data” in the Delimiter field.
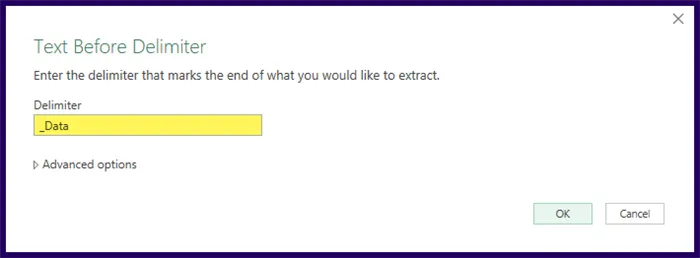
We could get away with just an underscore character here, but we’re “future-proofing” this, remember?
Once we progress to the next step in the Applied Steps list, we see a more fully-formed “Company” column.
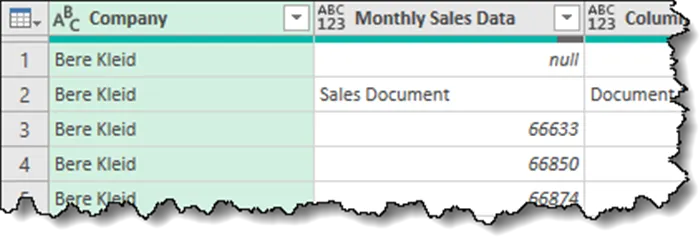
The problem now is that in our last step, was attempting to data type a column named “Source.Name”, but we have prematurely changed it to “Company” without informing it of such an action.

This step of data typing is unnecessary at this point since the column headings have not been handled properly, so we will delete this step and render this error irrelevant. Click the “X” to delete the “Changed Type” step.

Getting rid of repeated headers and empty rows
Additional issues include:
- Repeated column headers
- Null/empty rows at the bottom of files
We will correct these issues by applying additional transformations to the Transform Sample File. This way, the adjustments are made before the combining of records into the final table.
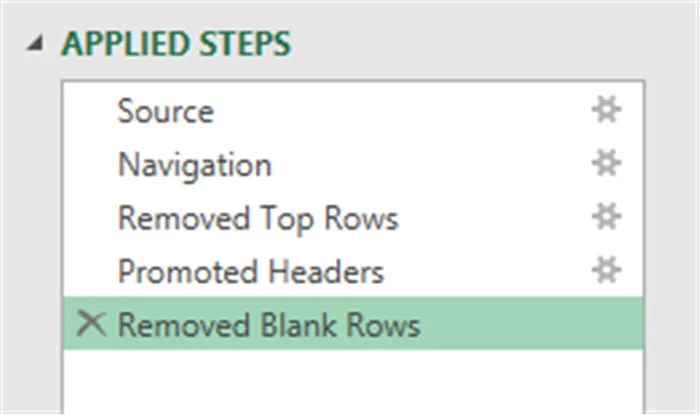
- Delete the “Promoted Headers” step
- Remove the top 2 rows (Home (tab) -> Reduce Rows (group) -> Remove Rows -> Remove Top Rows)
- Promote the first row to a header row (Home (tab) -> Transform (group) -> Use First Row as Header)
- Remove all blank rows (Home (tab) -> Reduce Rows (group) -> Remove Rows -> Remove Blank Rows)
Sometimes, Power Query tries to be a bit too helpful. Notice that after we promoted the header row, it automatically performed a data type analysis on our columns.
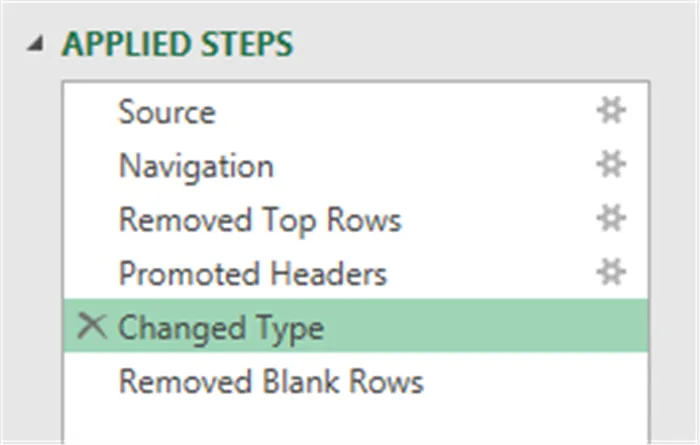
This doesn’t help us at this point since we will have to perform this again later once we combine all the data.
Let’s delete this step and apply it at a later point in the processing.
Returning to the Final Query
Switch to the “Report Files” query (left) to display the query that performs the final processing steps.
Click the heading of any column in the table and press CTRL-A to select all columns in the table.
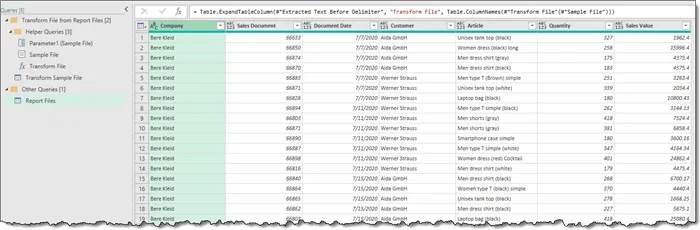
Perform a data type analysis by selecting Transform (tab) -> Any Column (group) -> Detect Data Type.

We now possess clean data that is ready to load into Excel.
Loading to Excel
We want to create a Pivot Table to report on aggregate sales by Company and by Customer.
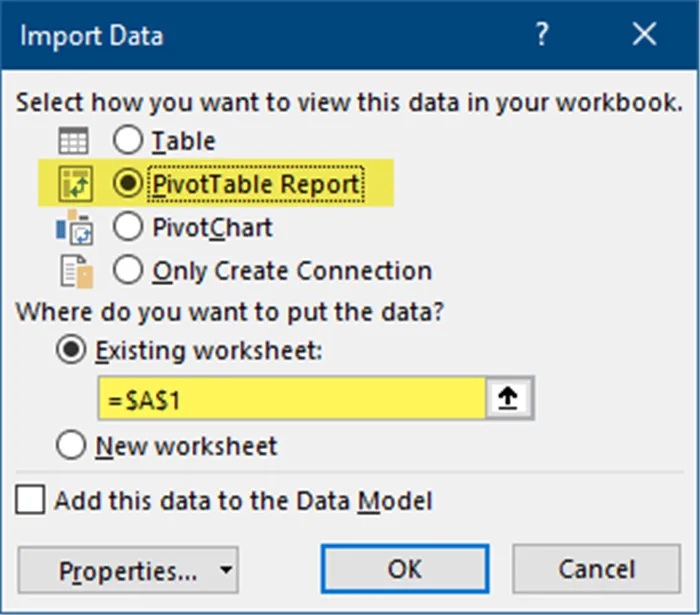
Select Home (tab) -> Close (group) -> Close and Load To…
In the Import Data dialog box, select “PivotTable Report” and select the load destination as the Existing Worksheet in cell $A$1.
Creating the Pivot Table Report
To create our report, we will place the following fields in their respective report areas:
- Sales Values in the Values section
- Customer in the Columns section
- Company in the Rows section
To make the report a bit easier to read, we will change the report layout to a tabular format by selecting the pivot table then click Design (tab) -> Layout (group) -> Report Layout -> Show in Tabular Form.
This produces the following report.
Featured Course
Power Excel Bundle

Adding New Data to the Report (Updating the Query)
As is expected in this scenario, new data is delivered that must be added to the existing dataset. This, in turn, will feed the Pivot Table and display the current collection of data.
Our new data file is from “Lucas Basics”. The number and names of the columns are correct; however, the order of the columns does not match the column order of the other company files.
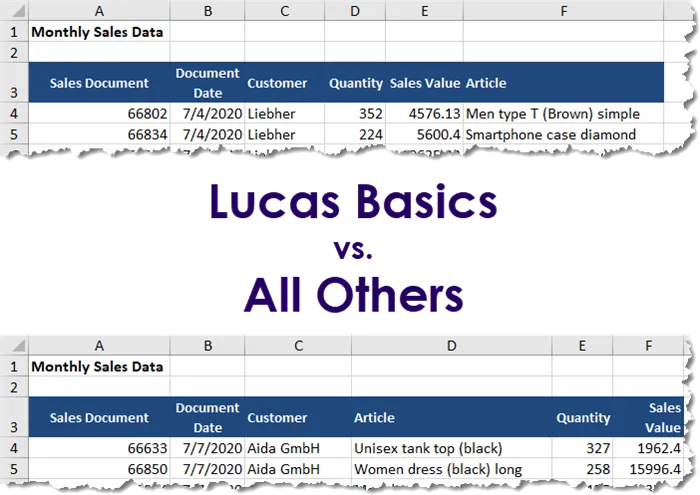
This will not be an issue for Power Query. Column order is not important, column naming is what is key.
REMEMBER: Power Query is case-sensitive. If you have a column named “Sales” and another column in a different file named “sales”, these will be treated as separate columns and not combined.
Place the newly received “Lucas Basics” file in the same folder as the other company files.
We can refresh the report by right-clicking the Pivot Table and selecting Refresh.
The “Lucas Basics” company data has been absorbed into the report.

Resolving the Case-Sensitivity Issue
If users are prone to changing the nature of the casing in the titles, you could fix each file manually before adding it to the report folder and refreshing the query… but that sounds like work.
Why not have Power Query capitalize the headings of files before combining them into a single table? This way, improper casing of titles is a non-issue.
There are many ways to standardizer the heading casing, but one of the most efficient ways is by using a bit of “M” code.
The underlying language for Power Query is called “M”. “M” stands for “mash-up”. The “M” language is covered in detail in the advanced portion of the Power Query course.
Creating a Table as Output
Instead of a Pivot Table report, suppose you wish to produce a traditional table as your output?
All we need to do is alter the output destination of the query.
In the Queries & Connections pane, right-click the “Report Files” query and click “Load to…”
In the Import Data dialog box, select Table as the destination and place the table either on a new worksheet or select a cell on an existing worksheet.
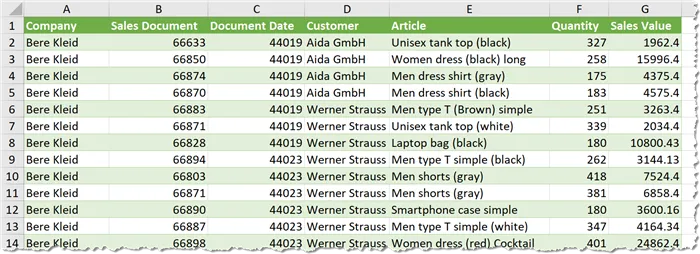
Our output is as follows.
Closing Thoughts
What we have gone through may seem like a lot of steps, but the good news is…
- Most of the steps were performed for us
- The query is resilient to column position differences
- The report is easily updated simply by placing the new data file in a folder and refreshing the report
If this feature doesn’t win you over to embracing Power Query as a go-to solution for solving data issues, then nothing will.

Leila Gharani
I'm a 6x Microsoft MVP with over 15 years of experience implementing and professionals on Management Information Systems of different sizes and nature.
My background is Masters in Economics, Economist, Consultant, Oracle HFM Accounting Systems Expert, SAP BW Project Manager. My passion is teaching, experimenting and sharing. I am also addicted to learning and enjoy taking online courses on a variety of topics.